

Photo by Andrik Langfield on Unsplash
Practical GitOps with AWS CodeBuild
How do we manage a serverless workload with code pushed to git?


Here we report on one specific implementation of GitOps for a serverless project on AWS. Surprisingly, AWS CodeBuild covers all our basic requirements for software automation in this context.
What does GitOps mean for a serverless project?
We started our serverless journey with Infrastructure-as-Code. Now we want to leverage GitOps for driving operations of our workload in production. Maybe you can find in this specific story some ideas for your own use case, different from ours.
GitOps requires Infrastructure-as-Code, change management rooted in git, and software automation. So let map these onto our specific context:
Infrastructure-as-Code - We have a convenient command
make deploythat creates or updates a ready-to-use serverless workload. This could run really any kind of infrastructure code such as HashiCorp Terraform, AWS CloudFormation, Pulumi, etc. For us, serverless on AWS means multiple Lambda functions, several DynamoDB tables, a CloudWatch dashboard, an Incident Manager response plan, Systems Manager Parameter Store, etc. Our code base is powered by Python, including Infrastructure-as-Code with the AWS Cloud Development Kit (CDK).Change management rooted in git - We deploy a public code base that is tuned with private settings. Our focus here is on change management of private settings. This is implemented with a private git repository on AWS CodeCommit and with pull requests managed collectively by our CloudOps team. A merge on the main branch triggers an update of the target serverless workload.
Explicit versioning of the code base - Since we use the main branch of a public code base, we want to configure which version is used either with a tag, e.g.,
v23.9.22or with an explicit git commit hash.Automated deployment - The build and update of a serverless workload is a linear sequence of shell commands. We put the software pipeline on a separate AWS account so that it cannot be confused with manual configuration. Hands-off, cloud engineers! A CodeBuild project provides a serverless and headless shell for all the commands we need. CDK commands executed in CodeBuild interact with AWS CloudFormation to manage the state of cloud resources.
How do we architect GitOps across multiple AWS accounts?
Our GitOps implementation spans multiple AWS accounts and is deliberately embracing serverless products from AWS. The following diagram represents the overall GitOps architecture put in place for our serverless use case.
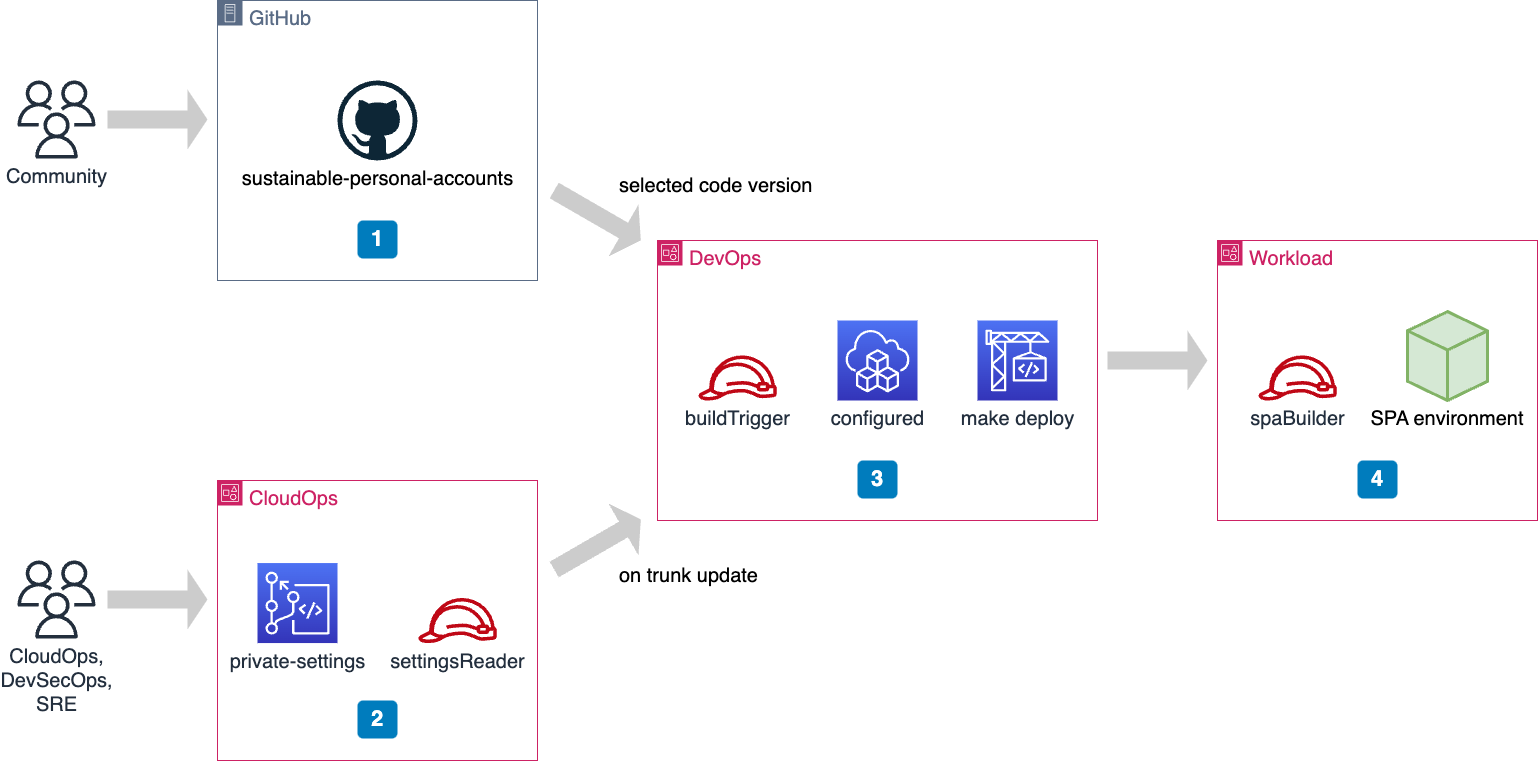
The main code base that we use is open source, and it is loaded from GitHub. This is the Sustainable Personal Accounts project, that automates the management of sandbox AWS accounts at scale. We do not want to update our workload in production on every update of this code base. Instead, we define explicitly which tag or commit we are using.
The exact configuration of our serverless workload is maintained as a private git repository on CodeCommit. Here the CloudOps team can tune every aspect of the workload with files in git repository. For our workload, this is meaning YAML and CSV files, configurations of Organizational Units, lists of AWS accounts and their configurations. We also have customized code snippets for the preparation and for the purge of AWS accounts. Changes of configuration files, of related code and of specific documentation are managed with pull requests on branches contributed by team members. CodeCommit supports pull requests from the CodeCommit console, from the AWS CLI and from AWS SDKs. Each update of the trunk branch induces an update of the serverless workload, and a change of its behavior. Private content is exposed via a specific IAM role and its trust policy.
When an update is triggered, a CodeBuild project is executed in a separate account, named
DevOps. This fetches the public code base from GitHub and the private settings from CodeCommit. This also combines the two set of files and runs non-regression tests. Then it builds or updates the target serverless workload.Since it has a serverless architecture, the target workload is built or updated one component at a time. The capability to act on this environment is granted via a specific IAM role and its trust policy.
Now that we have a global picture of our GitOps implementation, let focus on the automation itself, that is implemented with a CodeBuild project running shell commands.
What do we run in CodeBuild?
In our specific use case, the contract between cloud engineers and the automation is implemented in the Makefile. The automation invokes specific commands, e.g., make setup, make lint, make all-tests, make deploy. But the actual code that is executed for each command stays under control of cloud engineers. This is passed in the Makefile, along other infrastructure code pushed to git repository.
In other terms, the Makefile is playing here a role equivalent to a Jenkinsfile or .gitlab-ci.yml elsewhere.
If you have read our blog post Makefile is my buddy then this approach will sound familiar to you.
With these conventions in mind, here is the series of actions performed by the CodeBuild project on account DevOps:
Assume role from account
CloudOpsand fetch configuration from CodeCommit repository - Some configuration file defines which version of the public code base must be fetched from GitHub.Fetch code from GitHub and finalize the code base - This is implemented with
git clone. Then the commandmake setupis executed. This downloads and installs software dependencies. CodeBuild provides about 220 GiB of storage, so there is plenty of room for significant code base and dependencies. Then the private configuration files from CodeCommit are copied onto the original code base from GitHub.Test the code locally - This is implemented with commands
make lintandmake all-tests. If one of these commands fails, then the process does not go further.Assume role from target account and apply changes there - The update of the target environment is delegated to the command
make deploy. In our case, we rely on the AWS CDK to create and to update CloudFormation stacks.
You can look from GitHub at the buildspec that we are using. This is pretty straightforward.
How can you adapt this example for yourself?
In this post, we have described our specific usage of CodeBuild for GitOps. Maybe some of our guiding principles can resonate with you as well:
Cloud engineers want a GitOps experience that starts from the shell. Software automation should run the exact commands that they run on their workstations. We use
Makefilevirtual targets as the contract between the human beings and the automation.We act on a given environment independently from the others. Each workload environment on AWS its own CodeBuild project. Updates are triggered on code change, or on schedule, or when needed. Continuous Deployment is developed progressively, one target workload at a time.
Several AWS accounts are used for explicit management of permissions and for segregation of duties. The automation in CodeBuild has no super-power, and it assumes roles dynamically when needed. Nothing fancy here, only the best practices implemented in AWS IAM.
If you are looking for more details, then check the setup continuous deployment workbook of the Sustainable Personal Accounts project.
Are you managing your serverless workload as GitOps? Are you using CodeBuild for deployments and updates? Your ideas and feedback are welcome. Thanks for sharing innovative usages of serverless with us.